I recently used GPTHuman AI Review to analyze some content and the output wasn’t what I expected. I’m trying to understand if I set it up wrong, misunderstood its features, or if there’s a better way to get accurate, human-like AI feedback. Can someone explain how to properly use GPTHuman AI Review and share tips or best practices for getting reliable results
GPTHuman AI Review – My Experience
GPTHuman AI Review
I tested GPTHuman because of the promise on the homepage: “The only AI Humanizer that bypasses all premium AI detectors.” I wanted something I could run longer texts through without getting flagged. That slogan pulled me in, but the results did not match it.
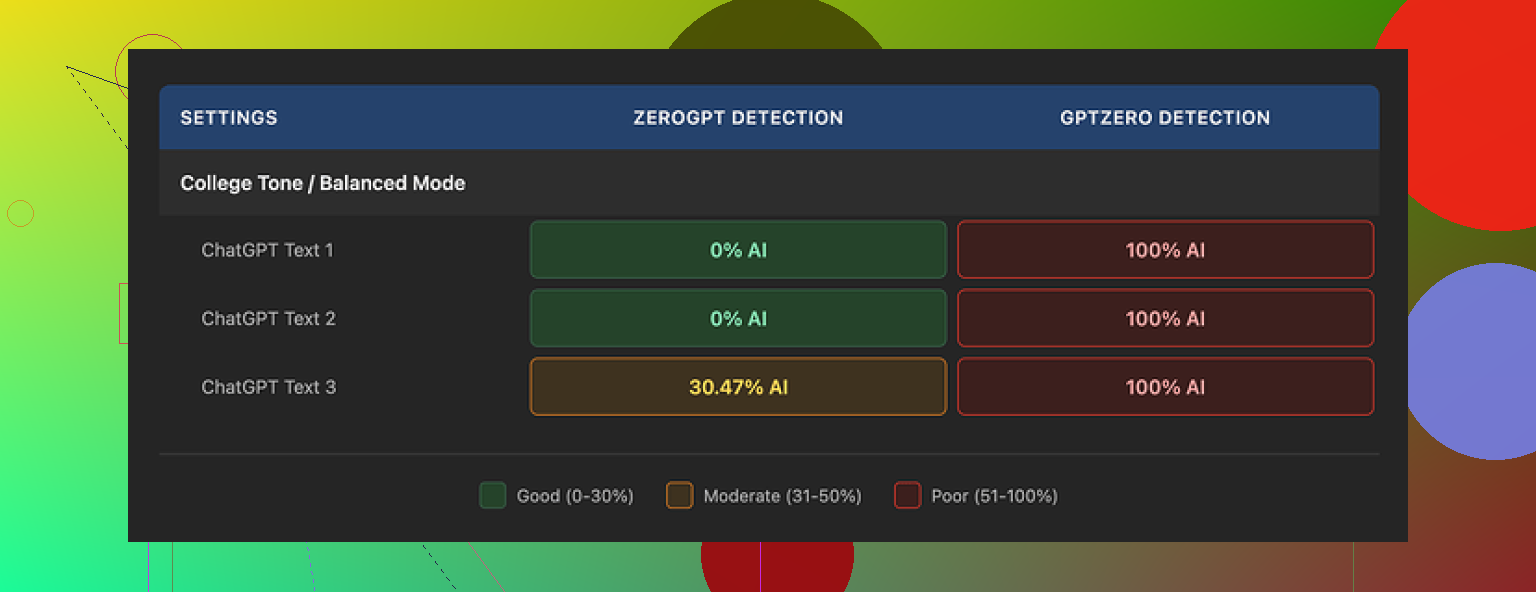
I ran three different pieces of text through GPTHuman, then checked every output against external AI detectors.
Here is what I saw:
• GPTZero: tagged all three GPTHuman outputs as 100% AI
• ZeroGPT: two outputs came back as 0% AI, the third was flagged at about 30% AI probability
They also have a built-in “human score” bar that looks encouraging, with high pass percentages. Those internal scores did not line up with what GPTZero and ZeroGPT reported. On their site it looked safe, on external tools it did not.
The writing quality itself was mixed. Paragraph formatting looked clean, line breaks made sense, and it did not spit out word salad. But once I read closely, stuff broke down.
Here are the problems I kept running into in the outputs:
• Subject and verb not agreeing, especially in longer sentences
• Sentences cut off halfway, like the model forgot how it started
• Word swaps that changed the meaning and made it sound off, like a bad synonym choice
• Awkward closings that felt stitched together, in one test the last paragraph was almost unreadable
So if you want something polished, you would need to spend time editing after the tool runs. It did not feel safe to paste straight into an email or a report.
On the pricing side, the free tier was tighter than I expected. You get about 300 words total, not per run. After that, it locks you out. To finish my normal test set, I ended up registering three different Gmail addresses, which got annoying fast.
Paid options at the time I checked:
• Starter: from $8.25 per month if billed yearly
• “Unlimited” plan: $26 per month
The word limit still applies on the top plan. Each individual output is capped at 2,000 words. So if you planned to run a long report or a chapter, you would have to split it into multiple chunks, which risks inconsistency in tone and structure.
A few policy details that stood out to me when I read through their terms and settings:
• Purchases are non-refundable
• Your inputs are used for AI training by default, you need to opt out manually
• They reserve the right to use your company name in their promotional material unless you tell them not to
If you work with sensitive docs, you should think through that last part before dropping anything private into the box.
While benchmarking, I tested GPTHuman next to a different tool, Clever AI Humanizer. I logged results for detection strength and usability. Clever AI Humanizer came out ahead in my runs, both in terms of detector scores and ease of use, and it was fully free at the time of testing.
If you want the full breakdown with screenshots and proof of the AI detection results, I posted everything here:
That thread has the raw outputs and detector screenshots if you want to see the exact scores instead of taking my word for it.
2 Likes
You didn’t set it up wrong. GPTHuman is mostly doing what it is designed to do, the marketing just gives people the wrong expectations.
Here is what is going on in plain terms.
- About “bypassing all premium AI detectors”
That line is the main trap. No tool beats all detectors all the time. Detectors change models, thresholds, and training data. Tools like GPTZero and ZeroGPT also often disagree with each other.
Your result is almost the same as what @mikeappsreviewer saw.
One detector calling it 100% AI. Another giving lower scores.
That spread is normal for this type of tool.
If you expected:
“Run text in, it turns into magic human prose that every detector calls 0% AI.”
Then the expectation was off. The tool leans toward changing style and statistics, not guaranteed stealth.
- Misunderstanding the “human score”
GPTHuman’s “human score” is its own metric.
It does not mean “GPTZero will pass this” or “ZeroGPT will pass this.”
Think of it like this:
• Internal bar = “Our model thinks this looks more human-like now.”
• External tools = “Our separate model thinks this is AI or not.”
These are different systems.
So when the internal bar is high and GPTZero still flags it, nothing is “broken.”
The score is just not aligned with those detectors.
You did not misconfigure anything there.
- Why the output feels off
You mentioned it did not match your expectation. There are a few typical reasons for that with GPTHuman type tools.
From tests and your description:
• Subject verb disagreement in long sentences
• Sentences cut off or lose the thread
• Weird synonym swaps that change meaning
• Endings that feel stitched or random
This happens because the model tries to push away from “AI looking” patterns. It over-edits and breaks grammar and flow.
If you start with clean AI text, you often end with messy “humanized” text that still looks AI to strong detectors.
So if you expected “clean, ready to send content,” that is where the mismatch sits. These tools are not focused on quality writing. They are focused on statistical disguise.
- Setup tips that sometimes improve results
You can tweak how you use GPTHuman to get slightly better output, but it will not fix the core limits.
Try these:
• Use shorter chunks.
300 to 500 words per run instead of large walls of text.
Long inputs increase the odds of broken sentences near the end.
• Run it once, not multiple times.
Double or triple “humanizing” often creates nonsense, not extra safety.
• Do a manual cleanup after.
Fix obvious grammar errors, sentence fragments, meaning changes.
Detectors usually care more about consistency and burstiness than perfect grammar, so manual edits help both quality and detection scores.
• Test with more than one detector.
If GPTZero screams AI but another tool gives a more mixed score, that is useful context.
Do not rely on one detector as “truth.”
- About your use case and expectations
You mentioned you wanted “accurate, hum…” which I assume is closer to “accurate, human sounding analysis or rewrite.”
If your goal is:
• Reliable analysis of your content
• Clear, coherent text
• Something safe to send to clients or as work
Then GPTHuman is the wrong core tool. It is a post-processor for style, not an analysis engine.
You are better off with this flow:
• Use a strong LLM to write or analyze (for example ChatGPT, Claude, etc).
• Then, if you insist on lower detector scores, run a light humanizer on top.
• Then always do a human edit.
If you only used GPTHuman expecting it to analyze and polish content, you did not misunderstand the settings, the product is built for a different priority.
- About GPTHuman pricing and data
One thing I partly disagree with from @mikeappsreviewer is on the pricing “being tight.” For a pure test, the free tier is enough. For ongoing use, the cap is painful.
Important points though:
• Word limits on “Unlimited” with 2,000 words per output.
• Inputs used for AI training by default, you need to opt out.
• Non refundable purchases.
If you work with client files or sensitive stuff, that data policy alone makes it a poor fit. No setting will fix that, only your workflow and tool choice.
- A more practical alternative
If your main goal is to reduce AI detection without trashing readability, Clever Ai Humanizer is worth a look.
Reasons it fits better for many users:
• Output usually keeps grammar stable while adjusting patterns.
• In tests by others, detector scores are more consistent.
• It is easier to work with if you need longer text processed in chunks.
You would still need to:
• Use short sections.
• Edit after the humanizer.
• Test on more than one detector.
No humanizer tool is a magic shield.
They all only lower probabilities and shift writing features.
- What you can do next, step by step
If you want to test if you misunderstood GPTHuman versus its limits, try this mini experiment:
- Take a 300 word AI generated paragraph.
- Run it once through GPTHuman.
- Run the output on at least two detectors.
- Read it out loud. Mark spots that sound off.
- Edit those spots manually, do not use another tool.
- Re test the final version on the same detectors.
You will likely see:
• You did not “set it up wrong.”
• Detectors do not drop to 0% consistently.
• Manual editing plus a lighter humanizer works better than relying on GPTHuman alone.
If that small test still gives you garbage results or detection remains high, it is not your fault. It is the limit of this specific tool and its marketing promise.
You didn’t set it up wrong. GPTHuman kinda did exactly what it is, just not what its homepage slogan makes you think it is.
I’m mostly on the same page as @mikeappsreviewer and @viaggiatoresolare, but I’d push back on one thing: I don’t think the “problem” is just marketing vs expectations. The core design is pretty shaky if you want reliable, human‑level output.
A few angles that might clarify what happened to you:
-
It’s not really an “analyzer”
The word “Review” in the name is confusing. It doesn’t seriously analyze your content like a proper LLM would. Its main job is to scramble style and token patterns so detectors have a harder time. That’s why you see:- Broken subject–verb agreement
- Cut‑off sentences
- Random synonym swaps that change meaning
It’s not trying to understand your text. It’s perturbing it.
-
Internal “human score” is basically vanity UI
That little green bar looks comforting, but it’s their own internal metric. It has almost nothing to do with how GPTZero, ZeroGPT, etc will classify things.
So when GPTHuman shows you a 90% “human” score and GPTZero screams 100% AI, that’s not you misusing the tool, that’s just two unrelated models disagreeing. Completely expected behavior. -
Detectors vs “bypass all” hype
No tool permanently “bypasses all premium AI detectors.” Detectors are literally trained on outputs from tools like this. It’s an arms race. If you buy into that tagline, you’ll always feel like you misconfigured something when in reality you just hit the ceiling of what’s technically possible. -
Quality tradeoff is baked in
You can baby it with: shorter chunks, one pass only, manual cleanup, etc. That might help a bit, but the fundamental tradeoff stays:- Stronger “humanization” = more statistical noise = worse readability.
- Softer “humanization” = better readability = detectors more likely to flag it.
There is no setting in GPTHuman that gives you “perfectly human, perfectly clean, 0% AI everywhere.” That knob just doesn’t exist.
-
Data & workflow issues
The bit in their terms about using inputs for training by default and splashing your company name in promo unless you opt out is not a tiny detail. If you’re feeding client material or internal docs, that’s a workflow red flag. That’s not you misunderstanding a feature; that’s the product having priorities that don’t match privacy‑sensitive use cases. -
If your real goal is “accurate, human‑sounding content”
This is where I lightly disagree with the “just expectations” take. For your use case:- You want accuracy
- You want human‑sounding
- You probably want something you can actually send
GPTHuman is simply the wrong primary tool. It’s like using a spam filter to write your emails.
A better setup in your case is something like:
- Use a solid LLM (ChatGPT, Claude, etc.) to actually analyze or draft the content.
- If you’re really worried about AI detection, run that through a lighter humanizer.
- Do a quick human pass: fix weird phrasing, restore any lost nuance.
For step 2, Clever Ai Humanizer has been mentioned already, and I’d lean toward that too, not because it’s magical, but because its whole design seems a bit more focused on keeping grammar and readability intact while nudging the statistical patterns. In practice that usually means:
- Less butchered syntax
- Fewer meaning‑changing synonym swaps
- Slightly more consistent detector scores
You’ll still need your own edit, but at least you start from something that doesn’t feel like a broken auto‑translate.
-
How to sanity‑check your setup next time
Instead of asking “did I set it up wrong,” ask:- Does this tool actually understand my text, or just mutate it?
- Is the internal score tied to any third‑party standard, or is it purely cosmetic?
- What happens if I paste the result into 2–3 detectors plus my own eyeballs?
- Could I explain to a non‑technical coworker what this tool is really doing?
If the honest answer to those is “it scrambles stuff and shows a pretty bar,” then you already know the limit.
So no, you didn’t really misconfigure GPTHuman. You just hit the boundary of what a “humanizer” like this can do, especially one selling the “bypass all detectors” fantasy. If your priority is accurate, human‑readble content that might test better, pairing a normal LLM with something like Clever Ai Humanizer and then doing a quick manual polish is way closer to what you actually want.
You didn’t set it up wrong; you expected it to behave like a writer and it behaves more like a noisemaker.
Where I slightly disagree with @viaggiatoresolare, @nachtdromer and @mikeappsreviewer: this isn’t just “marketing vs reality.” Architecturally, anything that tries to fool detectors without actually understanding content will always sit on a knife edge between:
- “Statistically weird enough to maybe confuse a detector”
- “So weird it breaks readability or meaning”
GPTHuman lives in that tension. The grammar glitches and chopped sentences you saw are not bugs, they are almost the product’s core strategy.
A few extra angles that did not get stressed enough:
1. Detectors are optimizing for patterns, not grammar
Everyone focused on “detectors disagree,” which is true, but the deeper issue is this: GPTHuman is attacking surface patterns (burstiness, repetition) while detectors have been moving toward higher level signals like:
- Consistent logical structure
- Overly neutral tone
- Overly balanced paragraph length
So even when GPTHuman ruins grammar, those higher level patterns can still scream “AI,” which is why GPTZero can stay at 100 percent. Smearing the text statistically is not the same as making it human.
2. Internal “human score” encourages the wrong behavior
When you trust that bar, you are tempted to crank settings toward maximum “humanization.” That is exactly where outputs start dropping verbs, swapping meanings, and producing stitched endings. In other words, the UI pushes you toward the worst quality zone.
3. Where a tool like Clever Ai Humanizer actually fits
If your real goal is something like “accurate, human readable content that doesn’t light up every detector,” you need a different priority stack:
- Meaning and accuracy first
- Readability and style second
- Detector friendliness third
Clever Ai Humanizer is closer to that, not because it magically passes everything, but because it typically preserves structure and sense while nudging style.
Pros of Clever Ai Humanizer in this context:
- Tends to keep subject–verb agreement intact
- Less aggressive synonym mangling, so meaning is safer
- More consistent behavior across longer chunks, so you do not have 3 different tones in one page
- Often gives you something you can lightly edit instead of rewrite from scratch
Cons you should be honest about:
- Still cannot guarantee “0 percent AI” on all detectors
- Can occasionally over-smooth text so it feels a bit generic
- You still need a manual pass if nuance or domain accuracy matters
- It remains a layer on top of an LLM workflow, not a replacement for proper drafting or editing
4. How to mentally reframe these tools
Instead of thinking “I’ll run my work through a humanizer to make it safe,” treat it as:
- An optional stylistic filter that might reduce some detector scores
- Something that always requires human review for serious use
- A piece of an LLM + editor + light humanizer pipeline, not the core engine
If you adopt that frame, GPTHuman’s behavior stops looking like you misconfigured it and starts looking like what it is: a fairly blunt instrument that trades a lot of clarity for a modest and inconsistent change in how some detectors react. Clever Ai Humanizer fits more cleanly into a modern workflow where you actually care about what the text says, not just how scrambled it looks to a classifier.